Наиболее популярные типы секретов в публичных и приватных репозиториях

Секретные ингредиенты безопасной разработки: исследуем способы точного и быстрого поиска секретов
Код — одно из ключевых мест хранения различных секретов. Всего один коммит может случайно унести в открытый доступ токен или пароль. Рассказываем, как создаётся функциональность поиска секретов в коде и какие критерии являются ключевыми.
22 июля 2025 г.
15 минут чтения
Точно и быстро искать секрет в коде — тривиальная задача, если знаешь конкретный формат секрета и осуществляешь поиск в своём проекте. Задача становится сложнее, если твой скоуп включает несколько проектов или один большой корпоративный монорепозиторий. И эта же задача становится вызовом, если область поиска — платформа для разработчиков, а формат твоего секрета — недетерминирован.
Меня зовут Денис Макрушин, и вместе с Андреем Кулешовым и Алексеем Тройниковым в этом году мы сделали POC платформы для безопасной разработки в рамках команды SourceCraft. Сегодня поговорим о функциональности поиска секретов. Наша appsec-платформа состоит из двух групп инструментов: анализаторы, которые требуют точной настройки, и слой управления, который отвечает за обработку результатов и интеграцию с инфраструктурой.
В этом материале пройдём стадию discovery для анализатора секретов: посмотрим на актуальные инструменты поиска секретов, их ограничения и определим направления для повышения трёх ключевых параметров Secret Sсanning: точность, полнота и скорость.
Роль секретов для защиты Non-Human Identity
Non-Human Identities (NHI) — элементы ИТ-инфраструктуры, которые выполняют в ней какие-либо действия и не являются человеком. Коллеги из Yandex Cloud уже рассказывали о связанных с ними рисках на примере сервисных аккаунтов в облаке. Также это могут быть сервисы, скрипты, CI/CD-раннеры, облачные ресурсы (ВМ, микросервисы, поды), IoT-устройства и прочее. Да, AI-агенты тоже. Многим NHI, как и пользователям, требуется проходить аутентификацию и авторизацию, а значит нужно носить с собой ключи от всех необходимых дверей. И эти ключи зачастую долгоживущие, поскольку в отличие от пользователя NHI не заботится о смене своего пароля.
Рост автоматизации и роли NHI в ней ведут к укреплению популярной тактики у атакующих: использование украденных учётных записей. В отчете «Data Breach Investigation Report 2025» от Verizon аналитики подтверждают, что в 2025 году украденные учётные записи являются главными «фигурантами» инцидентов. Атакующие всё чаще используют учётки от NHI: секреты от всевозможных сервисных аккаунтов, ботов, AI-агентов. Один из ключевых источников, который хранит в себе эти секреты, — код.

61% организаций имеют секреты, выставленные в своих публичных репозиториях, и если взглянуть на типы этих секретов, то всё многообразие можно разделить на два крупных блока:
- детерминированные строки: например, токены от известных облачных провайдеров и SaaS-приложений, сертификаты;
- и всё остальное: например, пароли в произвольном формате.
Отсюда следует наша цель: уметь быстро, полно и точно искать обе категории секретов.
«Быстро» — эта характеристика влияет на пользовательский опыт. Основной сценарий, в котором критична скорость поиска: режим анализа коммитов (push protection). Когда пользователь добавляет секрет в коммит и отправляет его в репозиторий, мы должны не допустить попадание этого коммита в кодовую базу. То есть мы должны не допустить утечку секрета. Режим push protection чувствителен к производительности инструмента анализа, поэтому в Public Preview нашей платформы мы сфокусировались на анализе коммитов и двух других характеристиках: «полно» и «точно».
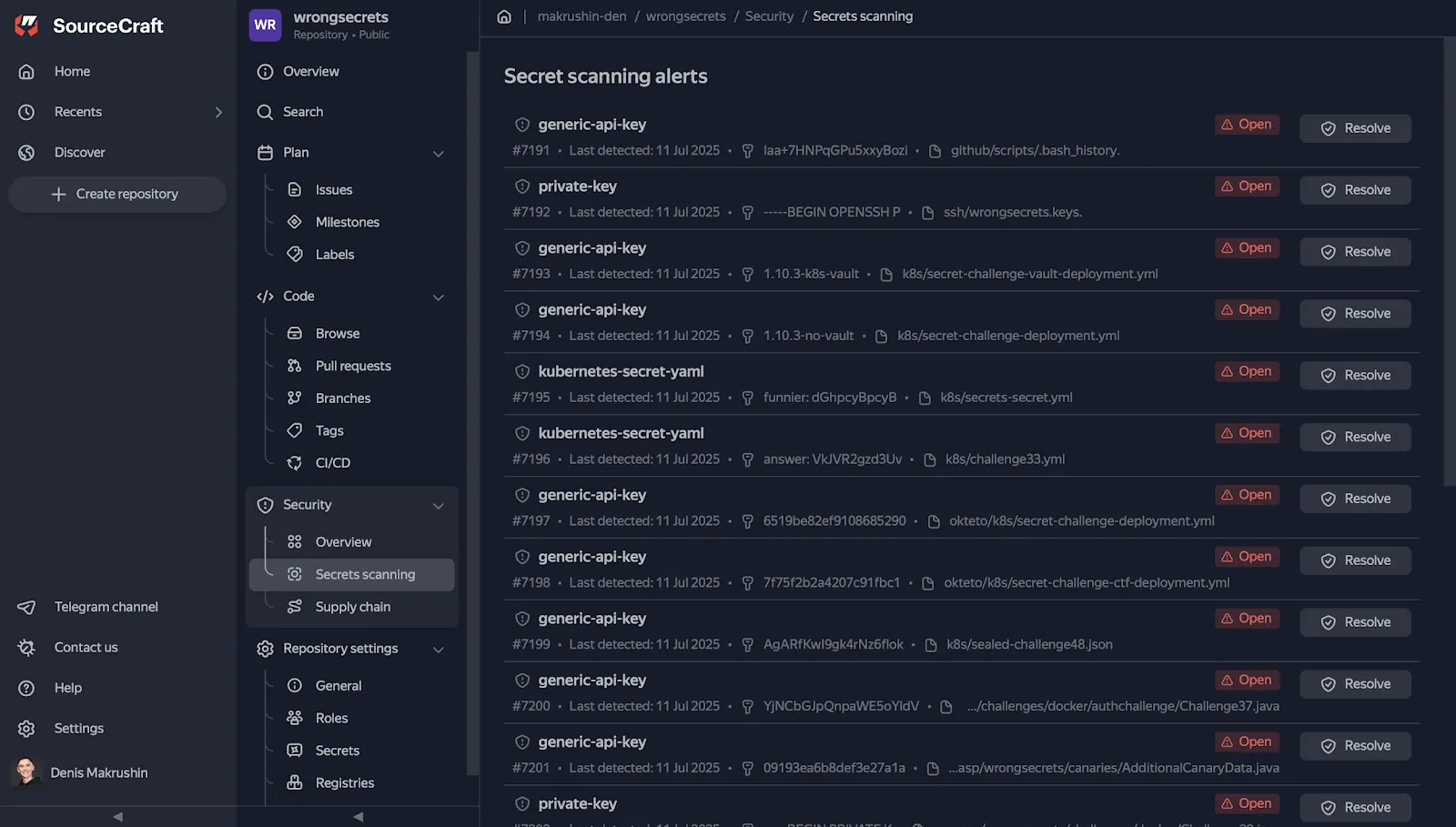
Поиск секретов с помощью Gitleaks в истории коммитов для репозитория SourceCraft
Сравнение инструментов для поиска секретов
В 2022 году мы уже рассматривали распространённые инструменты. С тех пор лидеры только укрепили свои позиции, и это подтверждают тесты.
Чтобы оценить инструменты поиска секретов, исследователи извлекли данные из 818 репозиториев GitHub, подготовили специальный датасет SecretBench и провели на его основе сравнение популярных проектов. Авторы вручную проверили и разметили каждый обнаруженный секрет как «истинный» или «ложный». В итоге в этом наборе данных содержится 97 479 секретов, из которых 15 084 являются настоящими секретами, а остальные — шум.
Сравнение инструментов проводилось на основе нескольких характеристик, три из которых наиболее важные для нас: скорость сканирования, полнота и точность.
Полнота (recall) — это метрика, измеряющая долю корректно обнаруженных секретов (true positives, TP) от общего количества всех реальных секретов в коде. Полнота показывает способность инструмента не упустить релевантные случаи.
Recall = TP / (TP + FN)
Точность (precision) — это метрика, измеряющая долю корректно обнаруженных секретов от общего количества всех обнаруженных положительных объектов. Precision показывает, насколько точен и чист результат обнаружения.
Precision = TP / (TP + FP)
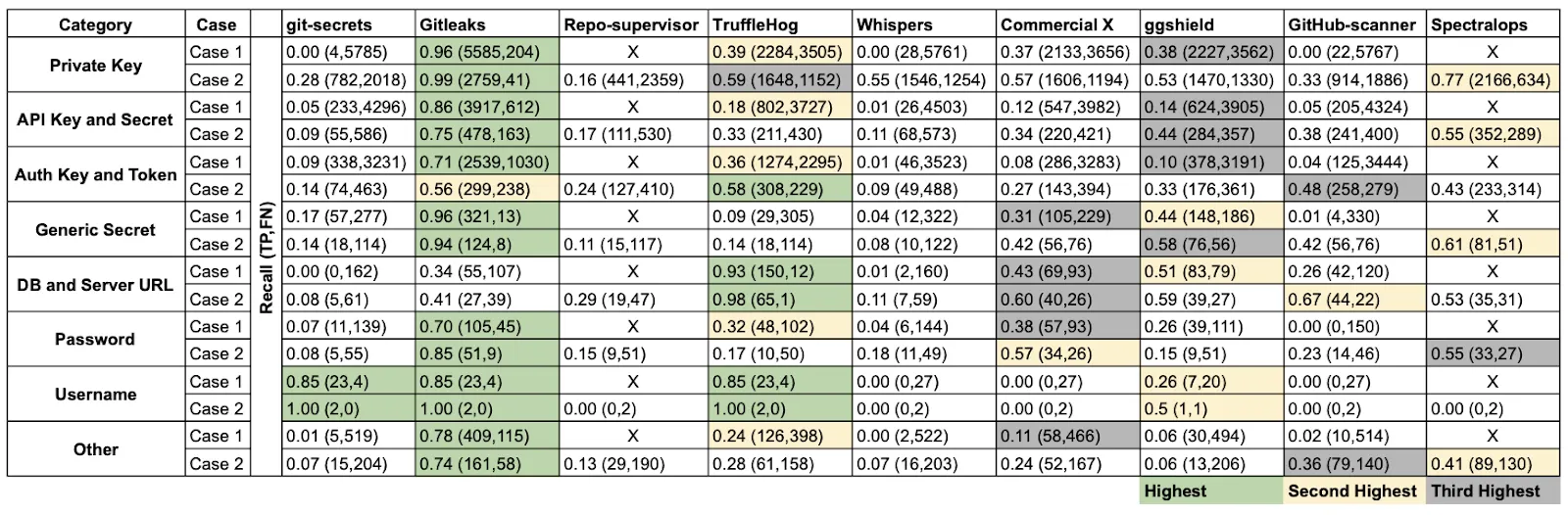
Полнота инструментов для каждой из категории секретов
Лидером среди опенсорс-проектов стал Gitleaks: у него 46% точности и 88% полноты. А ещё авторы сделали ключевой вывод:
«На данный момент нет ни одного инструмента, который обладал бы одновременно высокими показателями точности и полноты»
И тем не менее, Gitleaks представляет из себя оптимальную комбинацию скорости сканирования и полноты. Вместе с широким и регулярно пополняемым набором правил он позволяет нам достичь одной цели из двух, которую мы поставили в рамках Public Preview нашей платформы: обеспечить полноту сканирования. И делает при этом быстрее конкурентов.
Или уже нет.
Новый и очень быстрый Kingfisher
Недавно команда MongoDB опубликовала инструмент Kingfisher, который обладает рядом преимуществ относительно других опенсорс-проектов. Во-первых, он написан на Rust, а значит есть плюсы перед Golang-инструментами за счёт ускорения потока обработки. Это даёт ощутимый выигрыш в производительности при сканировании больших объёмов кода, например, монорепозиториев или всей истории коммитов.
Во-вторых, используется Hyperscan — быстрый движок для поиска по регулярным выражениям, который может одновременно обрабатывать тысячи шаблонов за один прогон. Regex matching занимает до 90% от всего времени сканирования, поэтому наличие этого движка позволяет отбросить Gitleaks, который использует стандартные regex-средства в Go.
И в‑третьих, кроме regex-движка ещё используется инструмент для синтаксического анализа кода — Tree-Sitter. Строит AST-дерево, чтобы понимать, где в коде находятся строки, комментарии, переменные, и проводить поиск только в нужных местах. Это помогает лучше понимать контекст, в котором находится секрет, и точнее его интерпретировать. Но эту функцию также лучше применять для больших файлов.
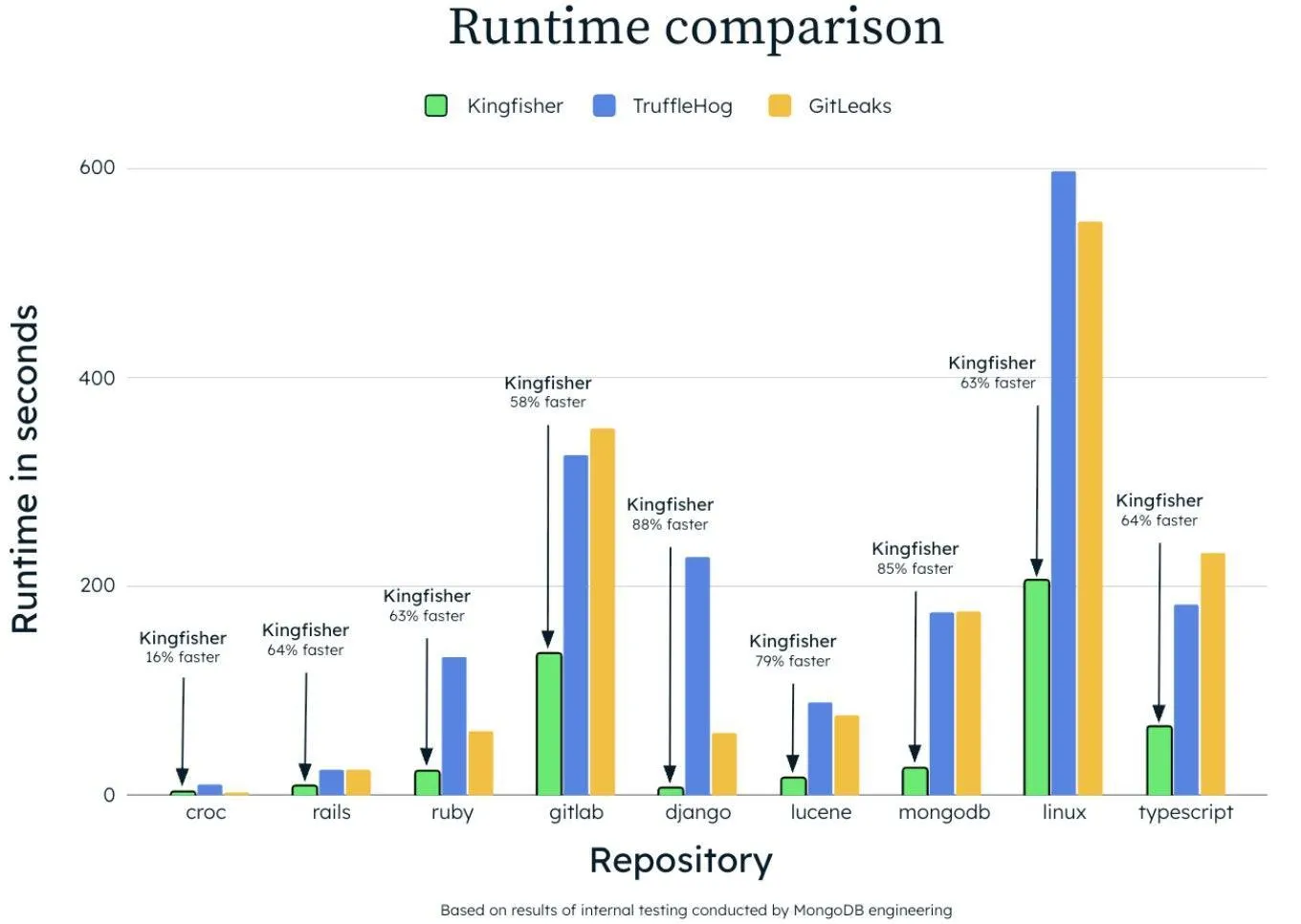
Сравнение производительности Kingfisher с конкурентами
Результаты внутренних тестов Kingfisher от авторов показывают кратное преимущество в скорости. Ещё можно заметить небольшое преимущество инструмента на небольших проектах. Появилась гипотеза: возможно, Kingfisher хорош в задачах, где важно сканировать большие репозитории и файлы, но может не давать такого преимущества при сканировании в режиме push protection.
Чтобы проверить гипотезу мы взяли небольшой проект sample_secrets и провели замеры производительности на нём для двух инструментов: Kingfisher и уже выбранного нами Gitleaks. Для получения замеров производительности используем Hyperfine — утилиту для точного сравнения производительности CLI-команд. Она запускает команду несколько раз, чтобы получить точные данные, и учитывает прогрев (warmup) в процессах загрузки инструментов.
Для чистоты замеров запускаем Kingfisher и Gitleaks в базовом режиме поиска секретов в каталогах и исключаем режим поиска в истории коммитов. Для Kingfisher отключаем дополнительную валидацию секрета. Получаем следующую команду для запуска:
hyperfine -w 3 -m 10 --style basic --export-json bench.json --ignore-failure 'gitleaks dir sample_secrets --no-banner --exit-code 0 --report-format json --report-path gitleaks.json' 'kingfisher scan sample_secrets --git-history=none --git-clone=bare --no-validate --no-update-check --format json -o kingfisher.json'

Результат измерений производительности на небольшом репозитории simple_secrets
Вероятные причины этого результата заключаются в суперспособностях Kingfisher: он компилирует 750 правил в Hyperscan, инициализирует Tree-Sitter, и это приводит к тому, что на маленьком наборе файлов стадия инициализации занимает значительную долю от всего времени сканирования. Проверяем эту гипотезу на репозитории побольше.

Kingfisher показывает улучшение производительности с ростом кодовой базы
Если взять крупный проект вроде Kubernetes, то Kingfisher обходит Gitleaks по скорости.

Kingfisher обогнал Gitleaks при сканировании репозитория Kubernetes
Делаем вывод: для режима push protection, где на стадии pre-commit важна скорость анализа, лучше использовать инструмент с минимальной стоимостью запуска и наибольшим количеством regex-правил. Для анализа средних и больших проектов, особенно с историей, важна точность, и здесь Kingfisher может усилить результат Gitleaks. При этом с задачей увеличения точности индустрия учится справляться не только сигнатурами, но и языковыми моделями.
Теперь сравним точность и полноту этих инструментов. Для этого возьмём репозиторий Wrongsecrets от OWASP и проведём сканирование. Результаты занесём в сравнительную таблицу.
| Показатель | Gitleaks | Kingfisher |
|---|---|---|
| Всего срабатываний (JSON-записей) | 831 шт. | 174 шт. |
| Уникальные находки (по fingerprint) | 825 | 174 |
| Уникальные строки-секреты | 343 | 139 |
| Дубликаты (один и тот же секрет, разные коммиты/файлы) | 484 повторных срабатываний | 0 (Kingfisher автоматически дедуплицирует результат) |
| Распределение правил (топ-3 обнаруженных типов секретов) | generic-api-key (95%), private-key (2%), kubernetes-secret-yaml (1%) | generic-password (30%), bcrypt-hash (23%), generic-secret (13%) |
| Live-валидация статуса (Kingfisher проверяет токены/ключи через API-валидацию, Gitleaks этой функции не имеет) | - | 26 «Active credential», 9 «Inactive», 139 «Not Attempted» |
| Пересечения (Gitleaks ∩ Kingfisher) | 57 секретов обнаружены обоими инструментами |
Какие выводы делаем из этой таблицы:
-
Gitleaks больше «шумит» на версиях/тегах.
781 из 825 уникальных срабатываний пришлись на правило generic-api-key. Среди них десятки строк вида wrongsecrets:1.12.0-no-vault, которые фактически являются Docker-тегами, а не ключами. Это значительно снижает точность. -
Относительно небольшое пересечение результатов (~17%).
57 секретов нашли оба инструмента. При этом Gitleaks нашёл 286 секретов (но значительная доля из них — ложноположительные (FP) версии/теги), Kingfisher обнаружил 82 секрета, из которых 26 строк классифицировал действующие («active credential»). -
Дубликаты в Gitleaks раздувают отчёт.
Один и тот же base64-пароль из .bash_history встречается 28 раз в разных коммитах. Kingfisher снижает шум, потому что использует внутреннюю систему дедупликации. -
Без дополнительных настроек сканирования Gitleaks выигрывает по полноте, а Kingfisher — по точности.
В текущем конфиге Gitleaks вылавливает любую «подозрительную» строку с высокой энтропией, и это даёт много ложных срабатываний. Kingfisher пропускает часть API-ключей, зато выдаёт меньше FP и сразу помечает находки, как активные или неактивные.
И основной вывод из этого сравнения заключается в сценариях применения инструментов. Для pre-commit проверок используем быстрый Gitleaks с набором строгих правил, а Kingfisher применяем для больших проверок релизов и истории коммитов.
Идеи для бэклога: увеличение точности поиска с помощью языковых моделей
К методам анализа энтропии, регулярным выражениям и сигнатурам, которые, как видим из сравнения, часто ошибаются и путают строку пароля с названием функции, добавились большие языковые модели (LLM). Обычные регулярки хороши там, где формат строк детерминирован (ключи, API-токены), но не учитывают многообразие структур строк паролей.
LLM снижают количество шума, потому что учитывают контекст. Команда Github подтвердила это в своём исследовании, но также отметила, что использование LLM требует линейного увеличения вычислительных ресурсов с каждым новым клиентом. И чтобы сэкономить немного ресурса, команде пришлось исключить из проверок все медиафайлы или файлы, которые содержали в названии «test», «mock», «spec»).
Из исследования можно позаимствовать следующие выводы:
- Регулярные выражения — это база для выявления детерминированных строк, но она сильно шумит при поиске паролей.
- LLM снижают шум и хорошо справляются с задачей поиска за счёт анализа контекста. При этом использовать LLM для активных и крупных репозиториев — дорого.
- Чтобы экономить ресурсы можно выбрать два пути: сокращать размер базы для анализа (как GitHub) или оптимизировать использование вычислительных ресурсов для анализа (как Wiz). Ещё лучше использовать оба подхода.
- Стратегии подсказок (промтов) для LLM влияют на точность обнаружения и на количество потребляемых ресурсов. GitHub попробовал стратегии Zero-Shot (дать модели только задачу, без примеров), Chain-of-Thought (попросить модель прийти к ответу через цепочку рассуждений), Fill-in-the-Middle (дать контекст «до» и контекст «после», затем попросить дополнить середину) и MetaReflection (после первого ответа модели попросить её проанализировать и доработать собственный ответ). В итоге MetaReflection дала лучшую точность.
Ключевое ограничение LLM исследователи Wiz предложили обойти с помощью малых языковых моделей (SLM). Они подтвердили гипотезу, что SLM могут быть эффективнее и дешевле LLM в задаче поиска секретов. Рецепт, который привёл к 86% точности и 82% полноты:
- Готовим данные для обучения модели: с помощью LLM проводим обнаружение и классификацию секретов из публичных Github-репозиториев. Можно использовать вторую LLM для оценки результата.
- Для повышения качества полученного датасета применяем алгоритмы MinHash и LSH (Locality Sensitive Hashing) для кластеризации полученных данных: объединяем похожие фрагменты кода в один кластер и убираем дубликаты.
- Выбираем модель, которую будем дообучать. Наша цель: не более 10 секунд на поиск секрета (доступный ресурс: однопоточная машинка с ARM).
- Добавляем наши «фильтры» к исходной модели: дообучаем небольшие матрицы внутри выбранной модели с помощью метода LoRA.
- Оцениваем результаты: следим за совпадениями на уровне файла (есть ли в нём секреты?) и совпадениями на уровне секрета (какой это тип секрета?).
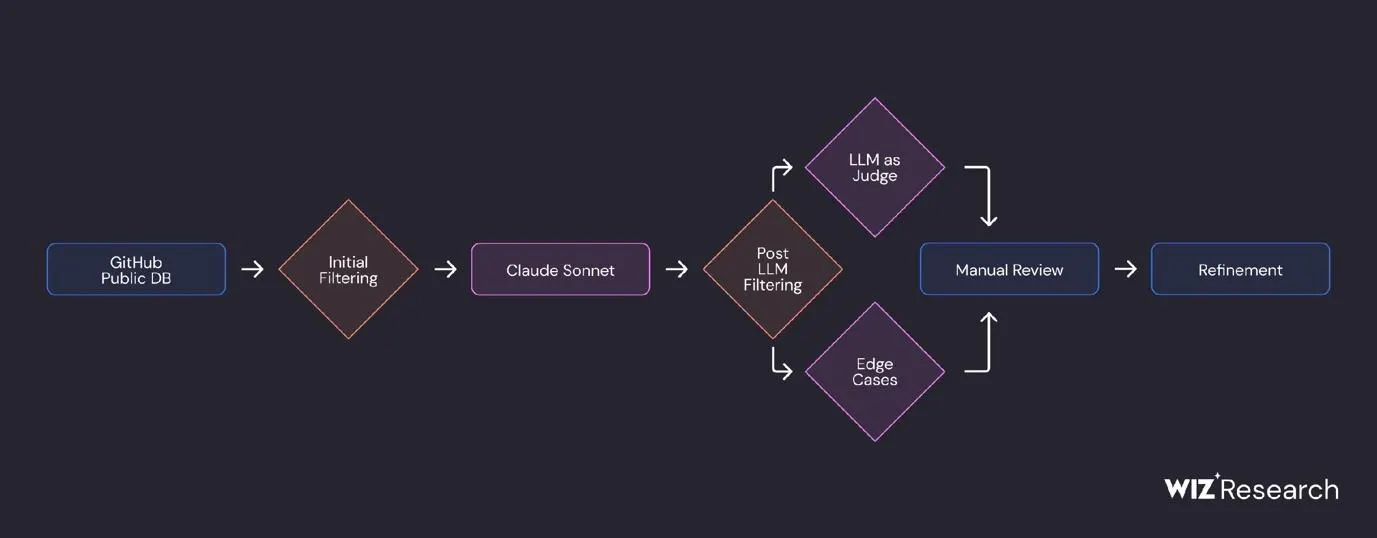
Пайплайн валидации секретов с помощью SLM от исследователей Wiz
Полученный результат не отменяет эффективность сигнатурных методов. Модель работает как дополнение к существующим правилам, обогащая результаты Gitleaks и Kingfisher за счёт анализа контекста.
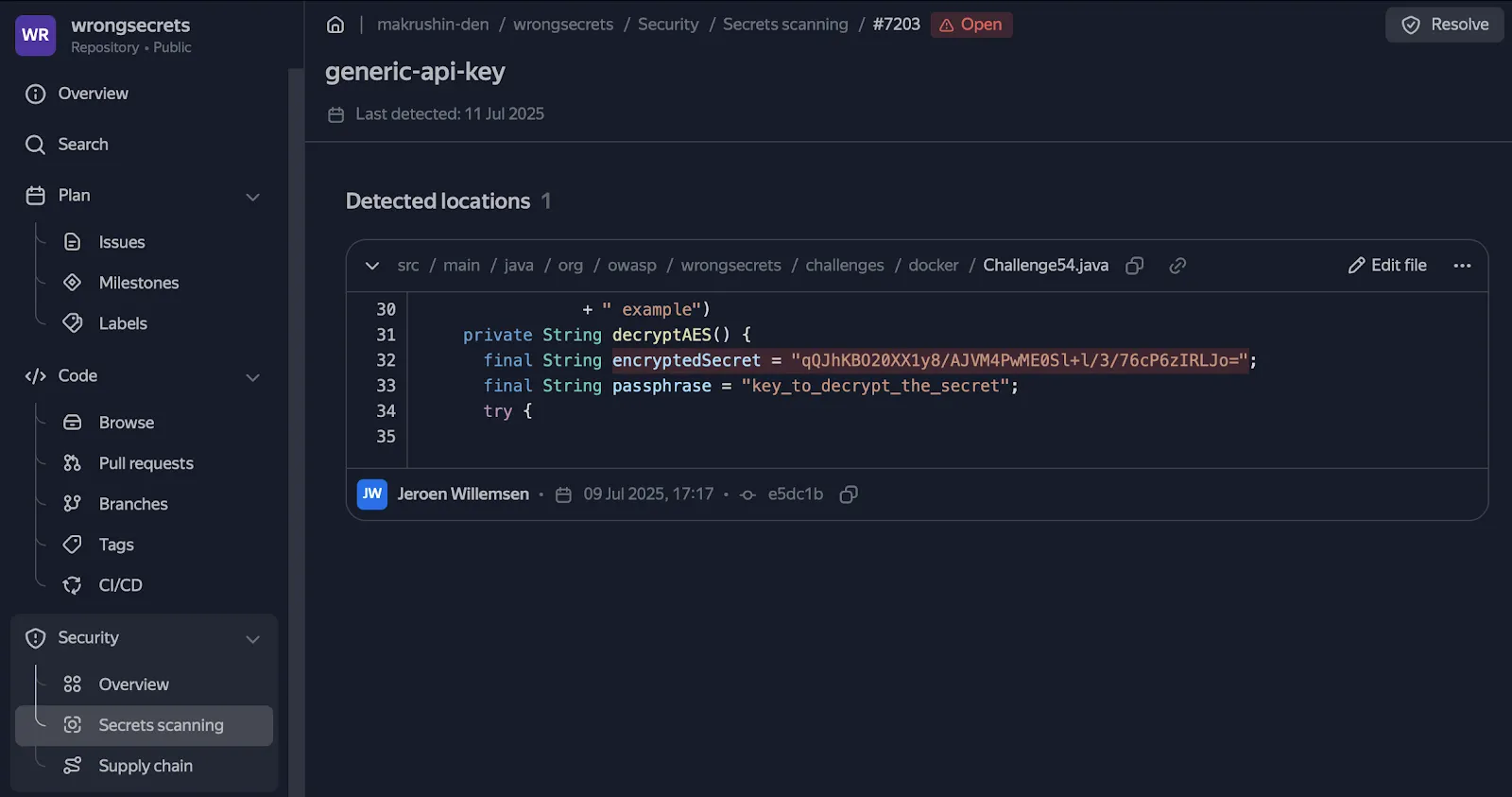
Пример контекста в SourceCraft, в котором обнаружен секрет
Контекстную информацию, которая влияет на вердикт, можно разделить на три крупных блока в порядке приоритета:
-
Синтаксический и семантический контекст (например, N строк кода рядом с секретом, имя переменной, тип AST-узла, язык файла).
-
Git-контекст (например, путь и тип файла с секретом, количество вхождений секрета в других коммитах или файлах, автор и дата коммита).
-
Метаданные сигнатуры, которая обнаружила секрет (идентификатор правила, энтропия, категория).
Комбинируя информацию в каждом из трёх блоков, можно оценивать точность и скорость языковых моделей. При этом важно понимать, что LLM в данной задаче представляет из себя дополнительный движок для скоринга, потому что многообразие строк, которые несут в себе секрет, — ограничено, а значит, сигнатуры пока ещё остаются базой для детекта. Добавляем в бэклог.